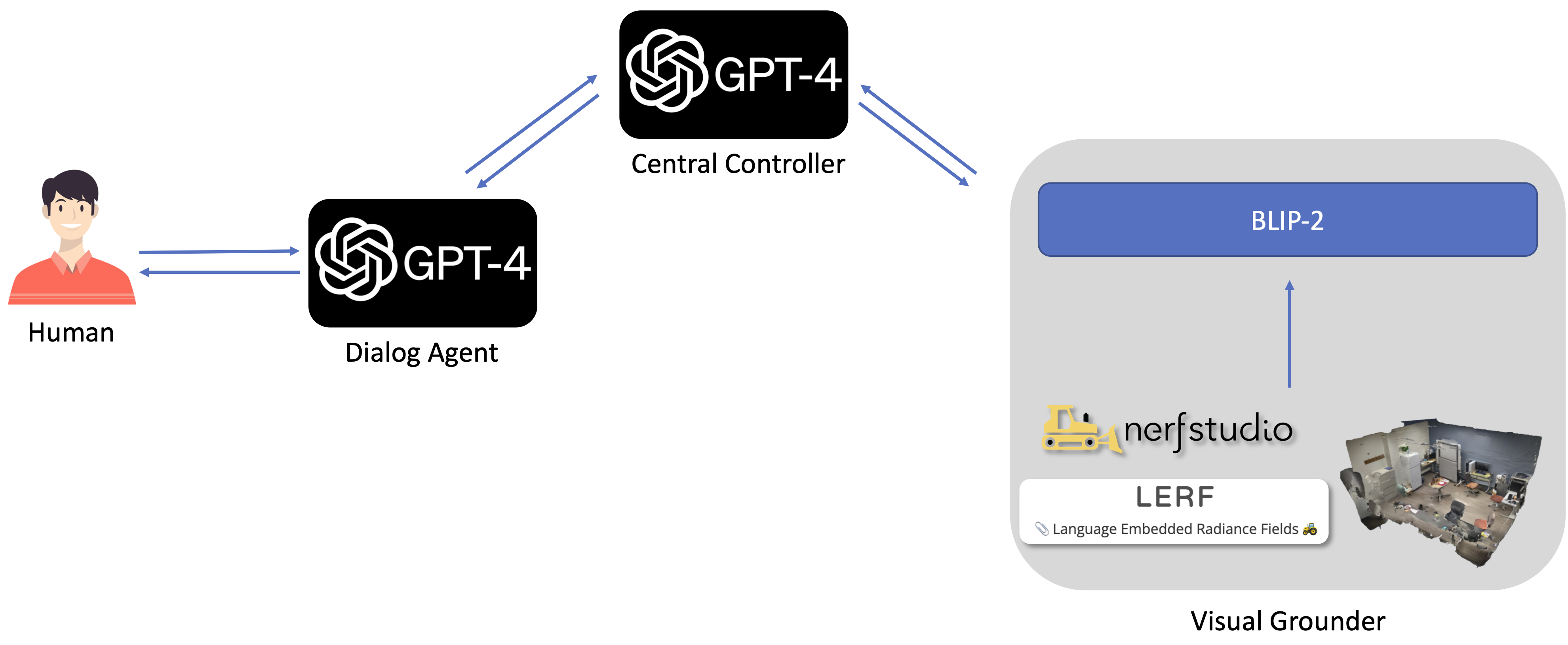
Abstract
We present the first method capable of localizing novel objects in 3D scenes using Neural Radiance Field (NeRF) and Large Language Models (LLMs) through iterative, natural language-based interactions. While grounding dialog to 2D images in multimodal dialog systems has been extensively studied, little work has been done in 3D object grounding. Furthermore, the existing 3D object grounding approaches predominantly rely on rigid, phrase-based manners, a stark contrast to how humans naturally refer to objects using short, natural phrases and iteratively clarifying their references.
Addressing these gaps, our work introduces a novel framework, "Chat with NeRF," that integrates interactive dialog systems with NeRF. This integration enables a more human-like interaction with 3D objects in a learned 3D scene representation, leading to a more intuitive and accurate object localization.